发布日期:2024-11-14 21:40 点击次数:100
2024年1月25日,中国东谈主工智能范围迎来一场所震——原土大模子本事厂商深度求索(DeepSeek)崇拜开源其推理大模子DeepSeek-R1。其性能发达与OpenAI同期旗舰模子o1不相高下,但考验本钱仅为后者的1/20,API调用价钱更是低至1/28,轮廓使用本钱骤降97%。这种“性能不当协、本钱砍到脚踝”的政策迪士尼彩乐园3,马上让DeepSeek-R1成为拓荒者社区、乃至总计大家的热议话题。

可是,跟着官方APP日活用户两周内破百万,API调用量激增300%,DeepSeek的行状器不胜重担,庸俗触发“行状器艰辛”指示。普通用户挟恨拜谒卡顿,企业客户则因要津业务中断风险运转另寻长进。金融、医疗等范围的企业率先转向第三方云行状。而银行、政务等对数据心事非常敏锐的企业则采选进行土产货化部署。
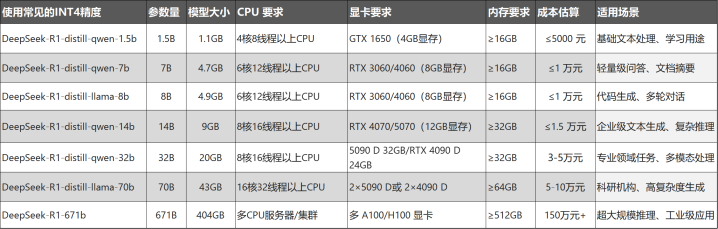
不外,除了上述这些财大气粗的国企央企之外,许多中袖珍企业、科研机构、高校和AI深爱者在预算有限的情况下,也思土产货部署DeepSeek若何办呢?幸亏,DeepSeek-R1推出了INT4量化模子,将原有的模子压缩为1/8支配,大大缩减了对硬件资源的需求。可即便如斯,满血版的DeepSeek-R1 INT4模子依然有671B参数(6710亿参数),运行需要至少6张NVIDIA A100 80GB或H100 80GB的显卡,整机本钱在150万以上。
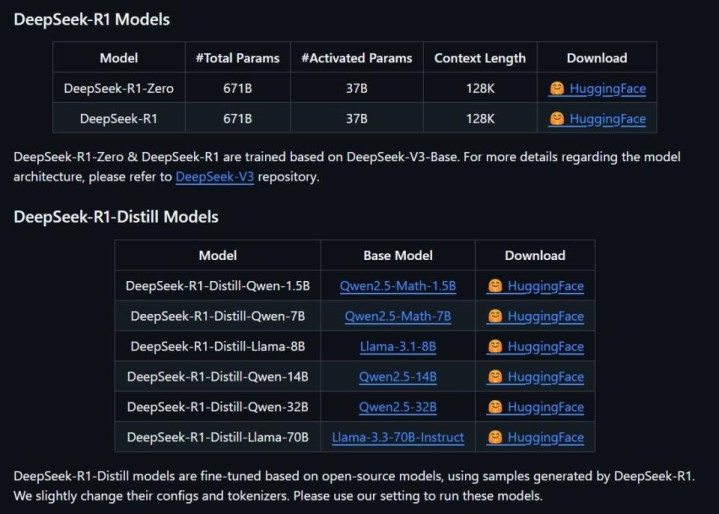
为了鼓励更多AI欺诈场景的需求,DeepSeek又推出了R1蒸馏版模子。所谓蒸馏模子(Knowledge Distillation),便是一种将大型复杂模子(教师模子)的学问移动到袖珍高效模子(学生模子)的本事。通过师法教师模子的输出,考验一个较小的学生模子,从而达成学问的传递。其所在是在尽可能保合手模子性能的同期,镌汰模子的经营复杂度和存储需求,使其更稳妥在资源受限的环境中部署。
满血版的DeepSeek-R1模子有6710亿参数,而蒸馏后的R1模子参数从700亿(70B)到15亿(1.5B)不等,参数范围越大,DeepSeek的智商就越强。打个比方,若是6710亿的R1是大学进修的话,那往下分袂是商酌生(70B)、大学生(32B)、高中生(14B)、初中生(8B)和小学生(1.5B)。若是论干活智商,14B以下的模子实用价值不高,玩玩尝个鲜可以,它的灵敏可能还不如你手机内部的小爱同学。是以,要思DeepSeek信得过成为你的AI职责助手,若何也得上32B,最佳是70B模子。
那运行这些DeepSeek-R1蒸馏模子究竟需要什么样的成就呢?咱们极端挑选了8款奢侈级显卡进行测试,得回的谜底有在料思之中,也有在料思之外。
咱们的PC成就如下:
CPU:英特尔U9 285K
主板:微星MEG Z890 ACE 战神
内存:金士顿FURY扞拒者 24GB*2 8400Mhz
硬盘:希捷酷玩540 1TB PCIe 5.0
显卡:NVIDIA GeForce RTX 5090 FE 32G
NVIDIA GeForce RTX 5090 D 32G
NVIDIA GeForce RTX 5080 16G
NVIDIA GeForce RTX 4090 D 24G
NVIDIA GeForce RTX 4070 12G
NVIDIA GeForce RTX 4060 8G
NVIDIA GeForce RTX 3070 8G
NVIDIA GeForce RTX 2080 Ti 11G
电源:鑫谷昆仑九重KE-1300P
散热:酷冷至尊ION冰界360水冷
部署器具:Ollama
GUI:AnythingLLM
系统:Windows11专科版 24H2
显卡驱动版块:Game Ready 572.43

率先是DeepSeek-R1 7B模子推理测试,8张显卡王人能平淡运行。发达最差的4060 8G也有45 Token/s。Token是臆度AI运行速率的一个所在,可以浅易瓦解成AI每秒生成的翰墨数目,Token值越高涌现推理速率越快。从咱们使用的主不雅感受来说,20 Token/s以上的速率是比较可以的发达,十足可以手脚坐褥力器具来使用。
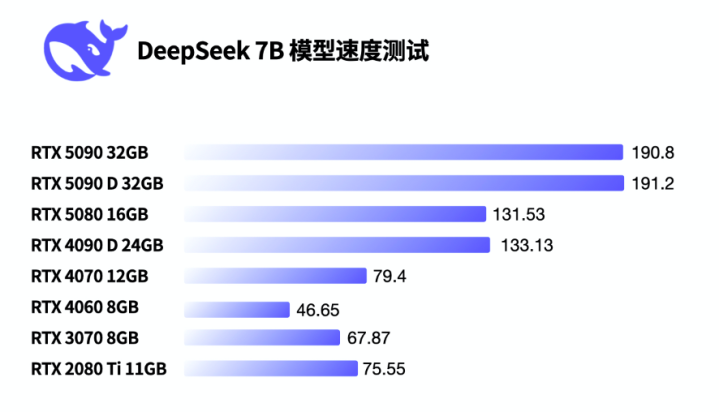
接着咱们进行了DeepSeek-R1 14B模子推理测试,这下8G显存的显卡非论中枢速率如何,获利王人大幅下落,运行速率唯有选藏的6 Token/s,也便是每秒蹦6个字支配。可以跑,但体验相对差一些。
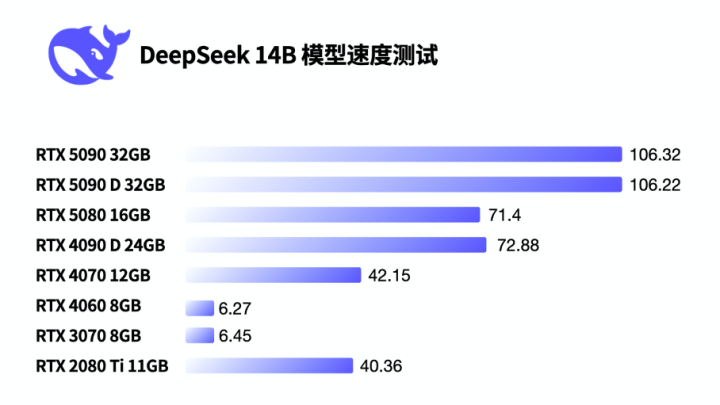
那为何8G显存的显卡性能下滑10倍呢?论断便是爆显存了。通过Windows任务看守器可以看到,14B模子将显存占满以后,有一部分数据跑到了分享显存里(也便是内存),而这部分数据其实是在CPU上跑,成果比GPU上慢太多,因此株连了举座的成果。
络续咱们测试,此次是DeepSeek-R1 32B模子测试。此次16G显存以下的显卡一齐报错,唯有RTX 5080可以拼集一战,至于速率嘛,迪士尼彩乐园2那叫一个目不忍视。原因照旧和前边相通,爆显存了。32B模子对显存的需求如确实20G支配。
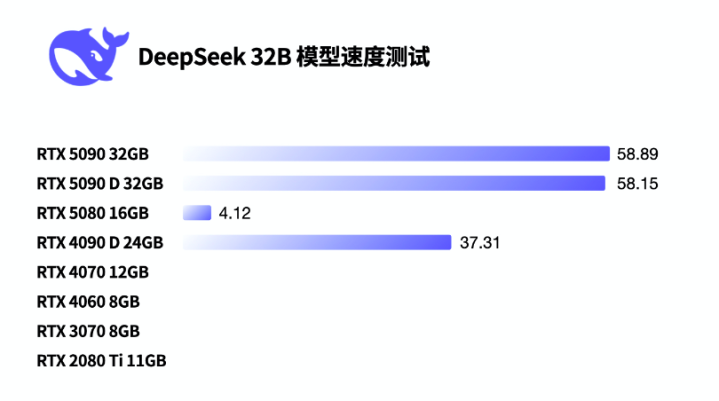
临了是DeepSeek-R1 70B模子测试。此次RTX 5080也歇菜了,唯有RTX 5090、RTX 5090 D和RTX 4090 D拼集能跑,不外速率嘛,也唯有选藏的5 Token/s。可以不雅察到,70B模子有30GB支配数据运行在显存(GPU)上,另外12GB支配数据运行在内存(CPU)上,加起来刚好是42GB多。
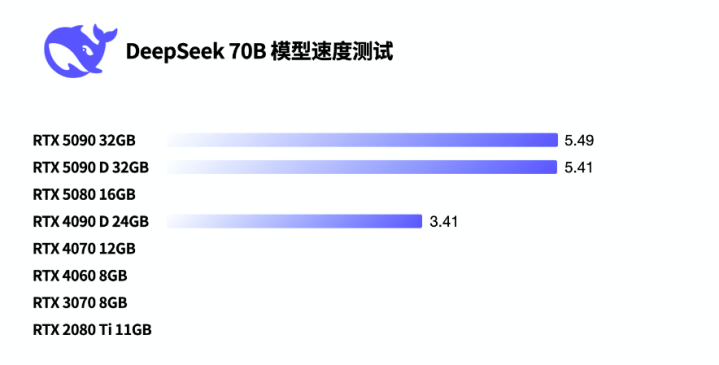
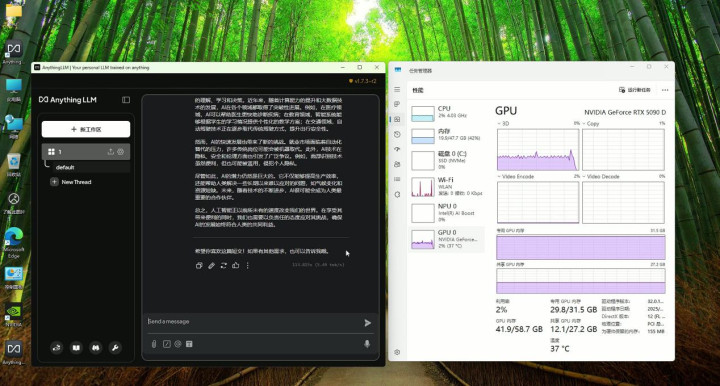
值得一提的是,无论跑阿谁模子,RTX 5090和RTX 5090 D的发达王人差未几。咱们议论了英伟达本事东谈主员,得回的复兴是运行DeepSeek这么的当代模子,其运行成果更依赖显存带宽,而非纯算力。说浅易点便是GPU中枢莫得跑满,是以看不出差距。
从以上测试咱们可以得出一个论断,若是你思土产货运行DeepSeek-R1蒸馏模子,比拟显卡的算力,显存的着急性更高一些。按照着急性排级的话:显存容量>显存带宽>核默算力。
不外,即便RTX 5090也不可很好地运行70B模子(5 Token/s的速率照旧太慢了),这小数有点让咱们失望。那有莫得更好的处理宗旨呢?有,加卡。咱们再加多一张5090 D显卡,总显存容量来到64GB,这下运行速率获胜飙到了23 Token/s,翻了4倍。
最新一期世界排名,特鲁姆普以173.12万英镑奖金稳居榜首。排名第二的囧哥威尔逊102.49万镑,与小特差了70多万。这个差距有多大?即便囧哥明年5月世锦赛夺冠收入50万英镑,小特不参赛,囧哥的排名也超不过小特。因此,在较长的一段时间内,特鲁姆普世界第一的位置恐怕无人撼动。

之前咱们缅思RTX 5090 D不救济NV-Link,没法多卡职责,没思到DeepSeek无谓NV-Link,两卡之间通过PCIE总线衔接,也能多卡联结。不外这也仅限于AI推理,若是是AI考验的话,遏抑可能就另当别论了。
探究到两张5090 D的价钱依然很贵,以当今的价钱加起来要5万元东谈主民币,有莫得更具性价比的搭配呢?于是咱们又测试了5090 D+5080的双卡组合(32GB+16GB=48GB显存),遏抑输出速率也相等快,接近20 Token/s。
到这里,咱们基本一经有了一个明晰的瓦解。DeepSeek R1 蒸馏模子如实能在保合手较高性能的同期,显赫镌汰对硬件的条目,部署本钱也大大镌汰,相等稳妥个东谈主拓荒者、袖珍企业和中等复杂度拓荒测试。
显卡采选方面,若是是采选7B模子,当今主流的奢侈级显卡(显存8GB以上的)基本王人能胜任。若是你条目高一些,需要14B模子,最佳采选12G显存以上的显卡。若是你思运行32B模子,最佳采选24G显存以上的显卡。若是你还不鼓励,思要上70B模子,那么双RTX 5090 D成就大约5090 D+5080会是更好的采选。

固然,若是你是大型企业和科研机构,需要进行超大范围的AI考验和推理任务,而况预算弥散迪士尼彩乐园3,那么DeepSeek R1满血版(671B)模子可能更稳妥你。DeepSeek R1满血版(671B)模子在FP16精度下,显存需求高达1.34TB,4-bit量化显存也需要约350GB,至少需要16张NVIDIA H100 80GB + NVLink/InfiniBand互联才气鼓励土产货化部署条目。